스크래핑을 시작 하기 전에 robots.txt를 확인하여 관련 정책을 확인해 줍니다.
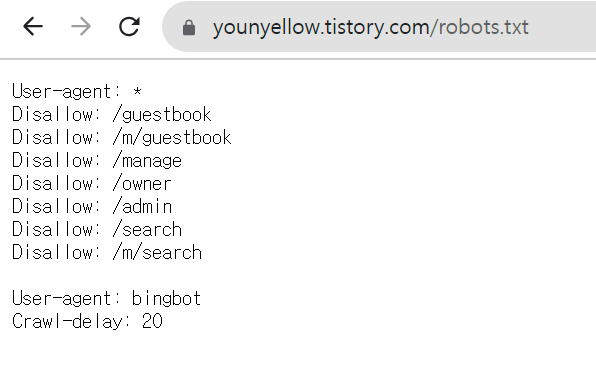
sitemap을 이용하여 스크래핑할 사이트 목록 불러온 후 정규 표현식을 이용하여 특정 링크들만 다시 리스트에 담아 줍니다.
import requests
from bs4 import BeautifulSoup
import xml.etree.ElementTree as ET
import re
class scrapper:
filterUrl = []
def sitemap(self):
url = 'https://younyellow.tistory.com/sitemap.xml'
response = requests.get(url)
if response.status_code == 200:
root = ET.fromstring(response.content)
pattern = r'^https:\/\/younyellow\.tistory\.com\/\d+$'
for url in root.iter("{http://www.sitemaps.org/schemas/sitemap/0.9}loc"):
if re.match(pattern, url.text):
self.filterUrl.append(url.text)
else :
print(response.status_code)
print(self.filterUrl)결과

filterurl을 for문을 돌며 필요한 데이터들을 객체형식으로 data에 저장해 줍니다.
import requests
from bs4 import BeautifulSoup
import xml.etree.ElementTree as ET
import re
class scrapper:
filterUrl = []
data = []
def sitemap(self):
url = 'https://younyellow.tistory.com/sitemap.xml'
response = requests.get(url)
if response.status_code == 200:
root = ET.fromstring(response.content)
pattern1 = r'^https:\/\/younyellow\.tistory\.com\/\d+$'
for url in root.iter("{http://www.sitemaps.org/schemas/sitemap/0.9}loc"):
if re.match(pattern1, url.text):
self.filterUrl.append(url.text)
else :
print(response.status_code)
self.getData()
def getData(self):
for o in self.filterUrl:
response = requests.get(o)
if response.status_code == 200:
soup = BeautifulSoup(response.content,'html.parser')
article = soup.select_one('section > article')
title = article.find('h1').string
content = article.select_one(".entry-content")
self.data.append({"title":title,"content":content})
else:
print(response.status_code)
print(self.data)
s = scrapper()
s.sitemap()결과
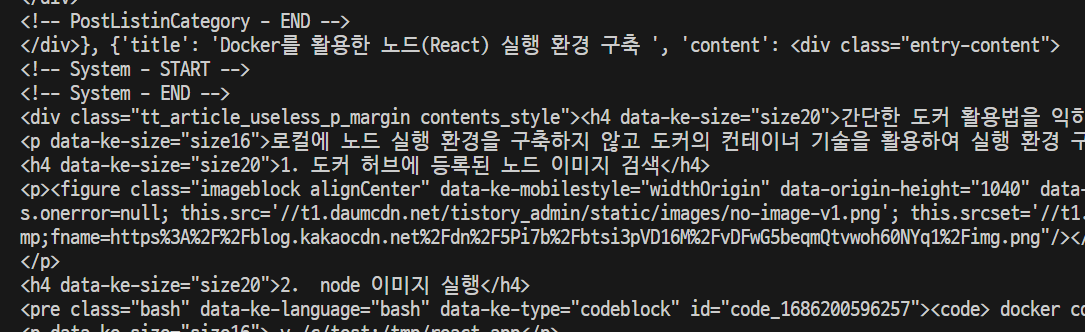
mysql 데이터 베이스 테이블 생성
+ int 가 길이 지정이 없어질 예정이라고 합니다. 길이를 지정하게 되면 warning이 뜨게 됩니다.
create table scrapping_data(
idx int not null auto_increment,
title varchar(100) not null ,
contents TEXT not null,
primary key(idx)
);mysql 데이터베이스 연동
필요한 라이브러리 설치
pip install pymysql
pip install cryptography코드
', ", 이모티콘 때문에 db에 들어갈때 오류가 발생하여 utf-8문자열로 인코딩하여 바이트 형태만든 뒤 다시 디코딩하여 데이터 베이스에 넣었습니다.
db에 데이터가 들어갈때 같은 이미 값이 존재하며 update 존재하지 않으면 insert 되도록 하였습니다.
import requests
from bs4 import BeautifulSoup
import xml.etree.ElementTree as ET
import re
import pymysql
class scrapper:
filterUrl = []
data = []
def sitemap(self):
url = 'https://younyellow.tistory.com/sitemap.xml'
response = requests.get(url)
if response.status_code == 200:
root = ET.fromstring(response.content)
pattern1 = r'^https:\/\/younyellow\.tistory\.com\/\d+$'
for url in root.iter("{http://www.sitemaps.org/schemas/sitemap/0.9}loc"):
if re.match(pattern1, url.text):
self.filterUrl.append(url.text)
else :
print(response.status_code)
self.getData()
def getData(self):
for obj in self.filterUrl:
response = requests.get(obj)
if response.status_code == 200:
soup = BeautifulSoup(response.content,'html.parser')
article = soup.select_one('section > article')
title = article.find('h1').string
content = article.select_one(".entry-content")
self.data.append({"url":obj,"title":title,"content":content})
else:
print(response.status_code)
self.connectDB()
def connectDB(self):
database = pymysql.connect(host='192.168.0.17', user='root', password='root', db='scrapping', charset='utf8')
cur = database.cursor()
for obj in self.data :
url = obj['url']
title = obj['title'].replace("'","''")
content = str(obj['content'].encode('utf-8'))
query = "insert into scrapping_data (url,title,contents) values (%s,%s,%s) ON DUPLICATE KEY UPDATE url=%s;"
val = (url,title,content,url)
cur.execute(query,val)
database.commit()
database.close()
s = scrapper()
s.sitemap()결과
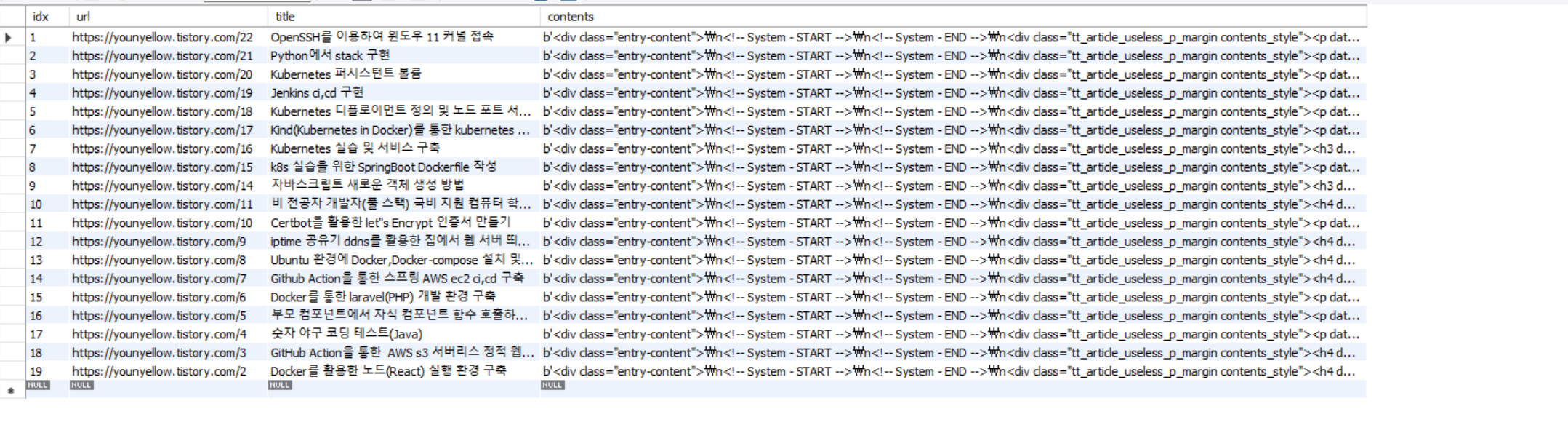
'Python' 카테고리의 다른 글
| Python에서 stack 구현 (0) | 2023.08.31 |
|---|
